-- 添加主键 Altertable tabname add primary key(col) -- 删除主键 Altertable tabname drop primary key(col) -- 创建索引 create [unique] index idxname on tabname(col….) -- 删除索引 dropindex idxname 注:索引是不可更改的,想更改必须删除重新建。
-- 创建视图 createview viewname asselectstatement -- 删除视图 dropview viewname 选择:select * from table1 where 范围 插入:insertinto table1(field1,field2) values(value1,value2) 删除:deletefrom table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 orderby field1,field2 [desc] 总数:selectcountas totalcount from table1 求和:selectsum(field1) as sumvalue from table1 平均:selectavg(field1) as avgvalue from table1 最大:selectmax(field1) as maxvalue from table1 最小:selectmin(field1) asminvaluefrom table1
3.select语句
1.普通查询
1 2 3 4 5 6 7
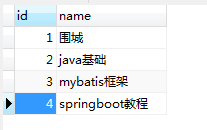
-- 查询整张表的所有列 select * from tb_user;
-- 查询指定列 selectid, namefrom tb_user;
select top 5 * from (select top 15 * fromtableorderbyidasc) table_别名 orderbyiddesc
2.distinct
1 2 3
-- 使用 distinict语句 (获得不同的值)(查询结果的所有列与别的记录) selectdistinctname,age from tb_user; selectdistinctnamefrom tb_user;
3.where
1 2
-- where 子句 筛选 select * from tb_user whereid = 1;
4.order by
1 2 3 4 5 6
-- 按id降序 select * from tb_user orderbyiddesc; -- 按id升序 select * from tb_user orderbyidasc; -- 多条件排序 select * from tb_user orderbyname,age asc;
5.and , or
1 2 3 4
-- and 子句 select * from tb_user wherename = 'yanghao'and age = 21; -- or 子句 select * from tb_user wherename = 'yanghao1'or age = 21;
6.like
1 2 3 4 5 6 7 8
-- like 子句 模糊查询 select * from tb_user wherenamelike'%hao'; select * from tb_user wherenamelike'yang%'; select * from tb_user wherenamelike'%yang%';
-- 个数 selectcount(*) as totalCount from tb_user; -- 总和 selectsum(age) as totalAge from tb_user; -- 平均值 selectavg(age) as avgAge from tb_user; -- 最大 selectmax(age) as maxAge from tb_user; -- 最小 selectmin(age) as minAge from tb_user;
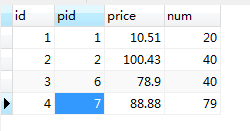
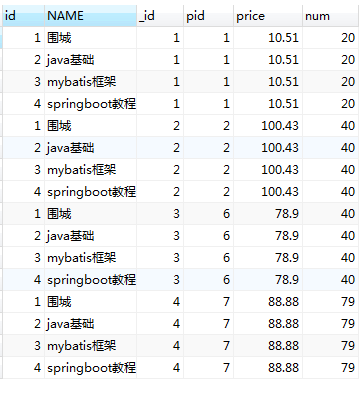
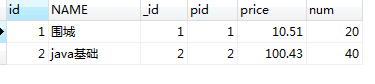
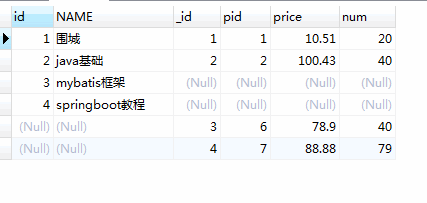
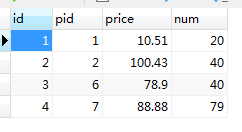
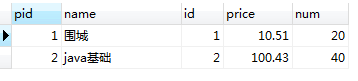
-- left join or left outer join SELECT p.id, p.NAME, pd.id AS _id, pd.pid, pd.price, pd.num from product p leftjoin product_detail pd on p.id = pd.pid;
在左连接的基础上加上过滤条件
1 2 3 4 5 6 7 8 9 10
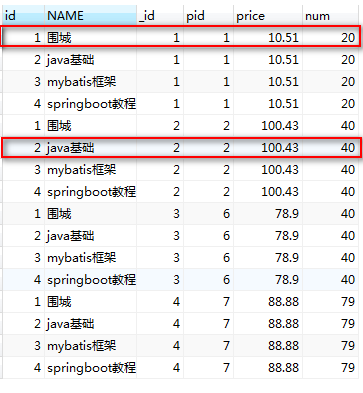
SELECT p.id, p.NAME, pd.id AS _id, pd.pid, pd.price, pd.num from product p leftjoin product_detail pd on p.id = pd.pid and p.id = 1
使用where进行过滤的
注意:在使用 left jion 时,on 和 where 条件的区别如下:
1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
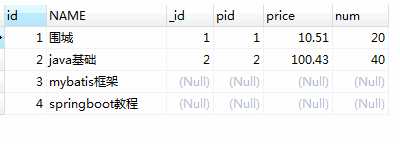
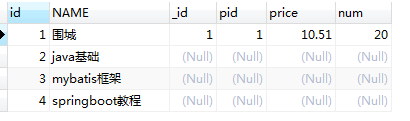
select p.id, p.name, pd.id as _id, pd.pid, pd.price, pd.num from product p rightjoin product_detail pd on p.id = pd.pid
加入过滤条件的有连接 on 后面接and进行过滤
1 2 3 4 5 6 7 8 9 10 11
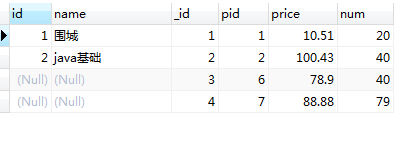
select p.id, p.name, pd.id as _id, pd.pid, pd.price, pd.num from product p rightjoin product_detail pd on p.id = pd.pid and pd.pid = 1
1 2 3 4 5 6 7 8 9 10 11 12
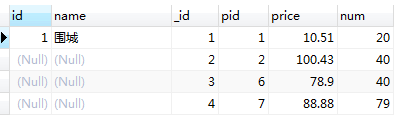
select p.id, p.name, pd.id as _id, pd.pid, pd.price, pd.num from product p rightjoin product_detail pd on p.id = pd.pid -- and pd.pid = 1 where pd.pid = 1
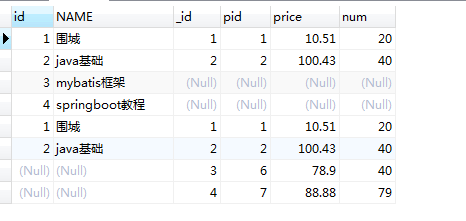
SELECT p.id, p.NAME, pd.id AS _id, pd.pid, pd.price, pd.num FROM product as p leftJOIN product_detail pd ON p.id = pd.pid UNION SELECT p.id, p.NAME, pd.id AS _id, pd.pid, pd.price, pd.num FROM product p rightjoin product_detail pd on p.id = pd.pid;
上面是使用的是union,不显示重复行,但是如果把union换成union all 那么就会把重复行显示出来,